얼렁뚱땅
졸프 기술블로그 본문
Flask + PeerJs를 통해 온라인 시험 환경 구현하기
우리의 팀프로젝트 주제는 웹 브라우저 기반 AI 시험 감독관이다. 온라인 시험 환경이 필요하기 때문에 화상채팅 기능을 먼저 구현하였고, 그 안에서 딥러닝을 사용하여 부정행위를 자동으로 탐지할 수 있는 서비스를 개발하였다. Zoom은 따로 어플리케이션을 다운받아야 하는 반면, 우리는 웹 브라우저만 있으면 사용할 수 있게 하기 위해 webrtc의 peerjs를 사용하였다.
기존에는 nodejs와 express, react를 사용해서 개발을 했었는데 코드가 너무 복잡해지고, 파이썬으로 구성된 딥러닝 부분과 nodejs의 자바 스크립트 코드를 합치기가 어려워서 코드를 모두 flask로 옮기는 작업을 하였다. 최종적으로 host 쪽 웹 페이지와, guest 웹 페이지를 따로 구현하고, flask를 통해 딥러닝 코드를 연결시켰다.
프론트 기준에서 페이지가 동작하는 큰 구조는 다음과 같다. (프론트는 간단하게만 보고 넘어갈 것이다!)
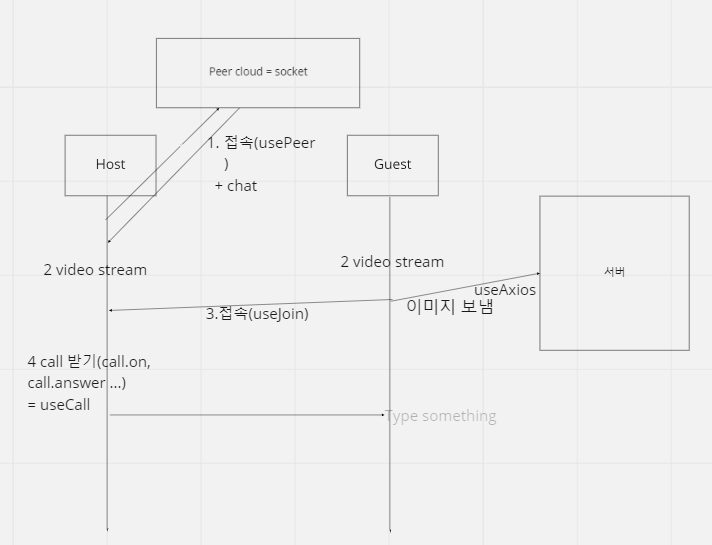
프론트
- Host: 시험 감독관
- Guest: 시험 치는 사람 (학생)
1. 가장 먼저 host에서 peerjs 서버에 접속해서 peer object를 생성한다. 이 과정에서 peer id를 받아서 peer.id에 저장해둔다. 추후 이 아이디를 통해 guest가 웹 페이지에 접속을 할 것이다. (즉, peer.id = Zoom 회의실 링크, 혹은 구글 미트 URL 이라고 생각하면 쉽다.) host는 id를 받아오면 connection을 기다리는 상태가 된다.
function initialize() {
peer = new Peer(null, {
debug: 2, //debug level:2 - print error and warnings
});
peer.on("open", function (id) {
// Workaround for peer.reconnect deleting previous id
if (peer.id === null) {
console.log("Received null id from peer open");
peer.id = lastPeerId; //reconnect됐을 때
} else {
lastPeerId = peer.id;
}
console.log("ID: " + peer.id);
recvId.innerHTML = "ID: " + peer.id;
peerId = peer.id;
status.innerHTML = "Awaiting connection...";
});
2. host와 guest 각각의 비디오 스트림을 서로 송출한다. function addVideo(stream) 함수를 만들고 4번 call을 보내고 답하는 과정에서 실행시킨다. stream 관련 코드는 몇 백줄이 넘어가서 여기에 다 넣기 어렵기 때문에 간단하게만 보고 넘어갈 예정이다.
3. peer id를 통해 guest가 host에게 접속한다. guest에서 id를 입력하게 되면 peer.on을 통해 conncetion이 이루어지고, 서로 실시간 이미지를 확인할 수 있는 data channel이 형성된다.
4. 그리고 call.on, call.answer를 통해 서로의 영상을 주고 받는다.
peer.call(
remotePeers[tmpRemoteStreamId],
remoteStreams[tmpRemoteStreamId2]
);
5. 마지막으로 우리는 실시간 화상통화 기능에 채팅 기능을 추가 하였다. 큰 틀만 보자면 addMessage function을 구현하고 그 안에서 실시간으로 채팅이 가능하도록 코드를 만들었다.
function addMessage(msg) {
var now = new Date();
var h = now.getHours();
var m = addZero(now.getMinutes());
var s = addZero(now.getSeconds());
//생략
function addZero(t) {
if (t < 10) t = "0" + t;
return t;
}
message.innerHTML =
//생략
}
function clearMessages() {
//생략
}
// Listen for enter in message box
sendMessageBox.addEventListener("keypress", function (e) {
//생략
});
// Send message
sendButton.addEventListener("click", function () {
//생략
});
// Clear messages box
clearMsgsButton.addEventListener("click", clearMessages);이제 딥러닝 부분을 살펴보자.
백앤드(딥러닝)
먼저 우리 프로젝트는 flask위에서 딥러닝이 돌아가기 때문에 기본 페이지인 app.py를 만들어 주고 다음 코드와 같이 기본 틀을 만들어준다.
app = Flask(__name__)
@app.route('/api/detection/', methods=['GET', 'POST'])
@app.route('/')
def web():
return render_template('index.html')
@app.route('/test/host')
def host():
return render_template('host.html')
@app.route('/test/guest')
def guest():
return render_template('guest.html')
if __name__ == "__main__":
app.run(host="0.0.0.0", port="5000", debug=True, ssl_context=(
'./ssl/localhost.crt', './ssl/localhost.key'))Routing
- index.html : 시작 페이지
- host.html : 감독관 페이지
- guest.html : 사용자(학생) 페이지
그리고 파일 구조는 다음과 같이 정리하였다.
Run
만약 localhost에서 실행시키고 싶으면 127.0.0.1로 하면 되지만, 우리의 프로젝트는 다른 기기에서 접속이 가능해야하기 때문에 0.0.0.0으로 설정하였다. 이렇게 해두면 host 컴퓨터의 ip 주소로 접근이 가능하다. 또한 웹캠을 사용하기 위해서는 반드시 ssl을 추가해주어야 한다. (이 프로젝트에서 ssl이 메인 기능은 아니므로 패쓰)
이제 이 기본 페이지(app.py)에 딥러닝을 추가하려고 한다.
손 인식 Hand Detection
우리는 Object detection에서 많이 쓰이는 YOLO 모델을 활용하여 손 인식을 하였다.
YOLO 모델이란?
YOLO 모델은 실시간으로 객체를 감지하고 인식하는 방법중 하나로 원리를 간단하게 설명하자면 예측하고자 하는 이미지를 SxS Grid cells로 나누고 각 cell마다 하나의 객체를 예측한다. 그리고 미리 설정된 개수의 boundary boxes를 통해 객체의 위치와 크기를 파악한다.
Yolo의 기본 모델은 많이 무거운데 우리 프로젝트 처럼 실시간이 중요한 경우 네트워크 상황에 따라 축소된 모델을 사용할 수 있다. (주로 개인 노트북에서 테스트 할때는 prn으로, 성능이 좋은 컴퓨터에서 테스트 해볼때는 normal로 설정했다.)
if network == "normal":
print("loading yolo...")
yolo = YOLO("models/cross-hands.cfg",
"models/cross-hands.weights", ["hand"])
elif network == "prn":
print("loading yolo-tiny-prn...")
yolo = YOLO("models/cross-hands-tiny-prn.cfg",
"models/cross-hands-tiny-prn.weights", ["hand"])
elif network == "v4-tiny":
print("loading yolov4-tiny-prn...")
yolo = YOLO("models/cross-hands-yolov4-tiny.cfg",
"models/cross-hands-yolov4-tiny.weights", ["hand"])
else:
print("loading yolo-tiny...")
yolo = YOLO("models/cross-hands-tiny.cfg",
"models/cross-hands-tiny.weights", ["hand"])
웹캠으로 받아오는 stream을 그대로 yolo 모델을 적용시킬 수 없기 때문에 사전에 이미지를 가공하는 과정이 필요하다. opencv에서 이미지를 읽기 위해서는 8 bit 로 된 것을 아스키로 변환시키는 과정이 필요하다. 또한 png 형식으로 통일하였다. 다음과 같이 코드를 추가해준다.
def detection():
frame = request.form.get('file')
img_data = np.frombuffer(base64.b64decode(
frame.replace('data:image/png;base64,', '')), np.uint8)
frame = cv2.imdecode(img_data, cv2.IMREAD_ANYCOLOR)
본격적으로 실시간 손 인식을 하기에 앞서 우리는 사용자가 부정행위를 했다는 증거가 필요하기 때문에 그 순간의 캡쳐사진을 따로 저장할 수 있는 코드를 작성하였다.
output_dir = './output_images'
os.makedirs(output_dir, exist_ok=True)
output_path = os.path.join(output_dir, str(userId) + ".hand." + str(now) + str(uuid.uuid4()) + ".jpg")
//detection 함수 안에서
cv2.imwrite(output_path, frame)
return json.dumps({"cheat": 1, "output_path": output_path})
다음은 손 인식 과정이다. 먼저 우리는 phone의 카메라와 노트북의 카메라를 구분했기 때문에 if문으로 핸드폰 카메라인지 확인해준 후, width, height, inference_time, results = yolo.inference(frame)를 통해 손을 인식한다.
- result = 인식된 손의 개수이다.
우리가 가정한 시험 상황은 아래와 같다.
- 2개의 손이 인식될 경우 : 정상
- 1개 또는 0개의 손이 인식될 경우: 부정행위 감지 -> 감독관에게 알림, 캡쳐본 저장
### 손 detect ###
if((device == "PHONE") | (device == "phone")): # 핸드폰 화면일 경우
width, height, inference_time, results = yolo.inference(frame)
print("%s seconds: %s classes found!" %
(round(inference_time, 2), len(results)))
# 여기에 사진 저장(값 0이면 캡쳐)
if len(results) < 2:
cheat = 1
# return json.dumps({"cheat": 1})
if cheat:
for detection in results:
id, name, confidence, x, y, w, h = detection
# draw a bounding box rectangle and label on the image
color = (255, 0, 255)
cv2.rectangle(frame, (x, y), (x + w, y + h), color, 1)
text = "%s (%s)" % (name, round(confidence, 2))
cv2.putText(frame, stid + text, (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX,
0.25, color, 1)
print("%s with %s confidence" %
(name, round(confidence, 2)))
cv2.putText(frame, stid, (90, 60),
cv2.FONT_HERSHEY_DUPLEX, 1.6, (147, 58, 31), 2)
cv2.imwrite(output_path, frame)
return json.dumps({"cheat": 1, "output_path": output_path})
return json.dumps({"cheat": 0, "output_path": output_path})
만약 인식된 손의 개수가 2개보다 작으면 cheat 라는 변수를 1로 변경하고 부정행위를 알린다. 일단 콘솔로도 찍히고, host에게 알림이 가도록 프론트에서 코드를 추가로 작성하였다.
그리고 부정행위가 감지될 경우:
1. 손의 위치에 박스를 그려주고 -> cv2.rectangle(frame, (x, y), (x + w, y + h), color, 1)
2. 무엇을 인식했는지 이름과 정확도를 나타내준다. (여기서는 hand) ->text와 cv2.putText 사용
3. 그리고 캡쳐된 화면을 저장한다. -> cv2.imwrite(output_path, frame)
실제로 코드를 돌려보면 다음과 같이 잘 인식되는 것을 확인할 수 있다. (결과물을 먼저 확인하고 실행방법은 아래에서 자세히 다룰 예정이다.)


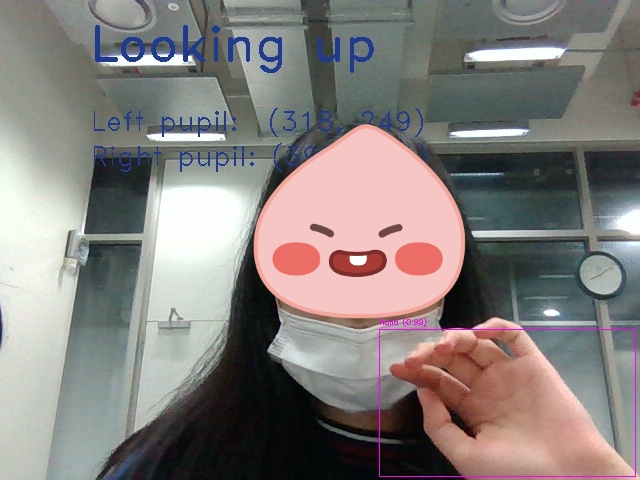
결과 분석
손가락 5개가 모두 구분이 가능한 경우 정확도가 99%까지 올라가지만 손가락 구분이 잘 안되는 경우 정확도가 떨어지는 것을 확인할 수 있다. 그럼에도 불구하고 손이 반쪽만 나와도 손이 있다는 것 자체는 잘 인식이 되고 있음을 알 수 있다. 우리 프로젝트는 손이 인식되는지 여부만 중요하지 손가락의 개수나 손 모양은 상관없기 때문에 이대로 사용하기로 했다.
사진에서는 눈 인식도 동시에 되고 있는데 아이트래킹 딥러닝의 경우 1학기 때 이미 구현되었고 내 파트가 아니기 때문에 자세한 내용은 생략하고자 한다.
실행
프론트 + 백앤드 (손 인식, 눈 인식) 기본 코드를 모두 작성했으면 이제 실행해보자.
실행하기전 확인할 것
1. flask, opencv, numpy가 있어야 한다.
2. 자신의 ip 주소 및 모델 위치 확인
3. ssl이 있어야 한다.
터미널을 열고 python app.py을 입력한다.
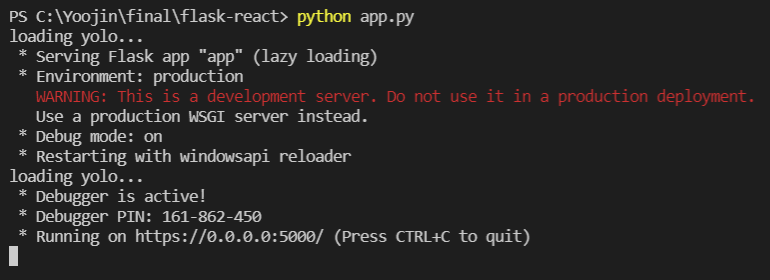
그러면 yolo가 정상적으로 작동하는 것을 알 수 있다.
여기서 Running on https://0.0.0.0:5000이라고 뜨는데 여기로 들어가면 안되고 https://본인_ip_주소:5000 로 들어가야 한다. (다들 아시겠지만 ip주소는 cmd 창에서 ipconfig 하면 나온다.)
그냥 아무것도 없이 port 5000으로 들어가면 index 페이지가 나오고, 나머지는 본인이 경로를 설정한대로 나올 것이다.
최종 결과물
- 프론트 + 백앤드 모두 완성시 나오는 웹페이지

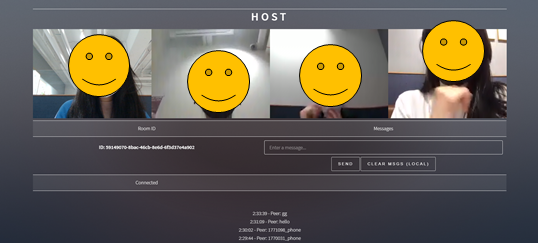
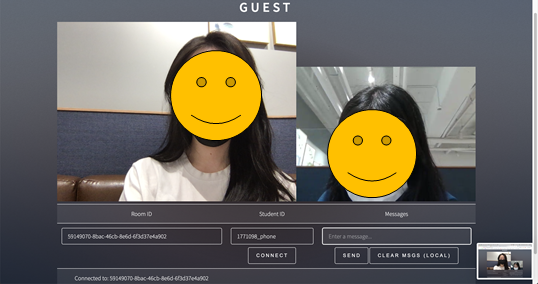
(학생들의 프라이버시를 위해 감독관 페이지에서만 모든 학생의 얼굴을 볼 수 있고, 학생 페이지에서는 본인과 감독관의 얼굴만 볼 수 있도록 설정하였다.)
삽질 후기!!!
그냥 버리기에는 우리의 시간과 노력이 너무 아까워서 블로그에라도 남겨두고자 한다.
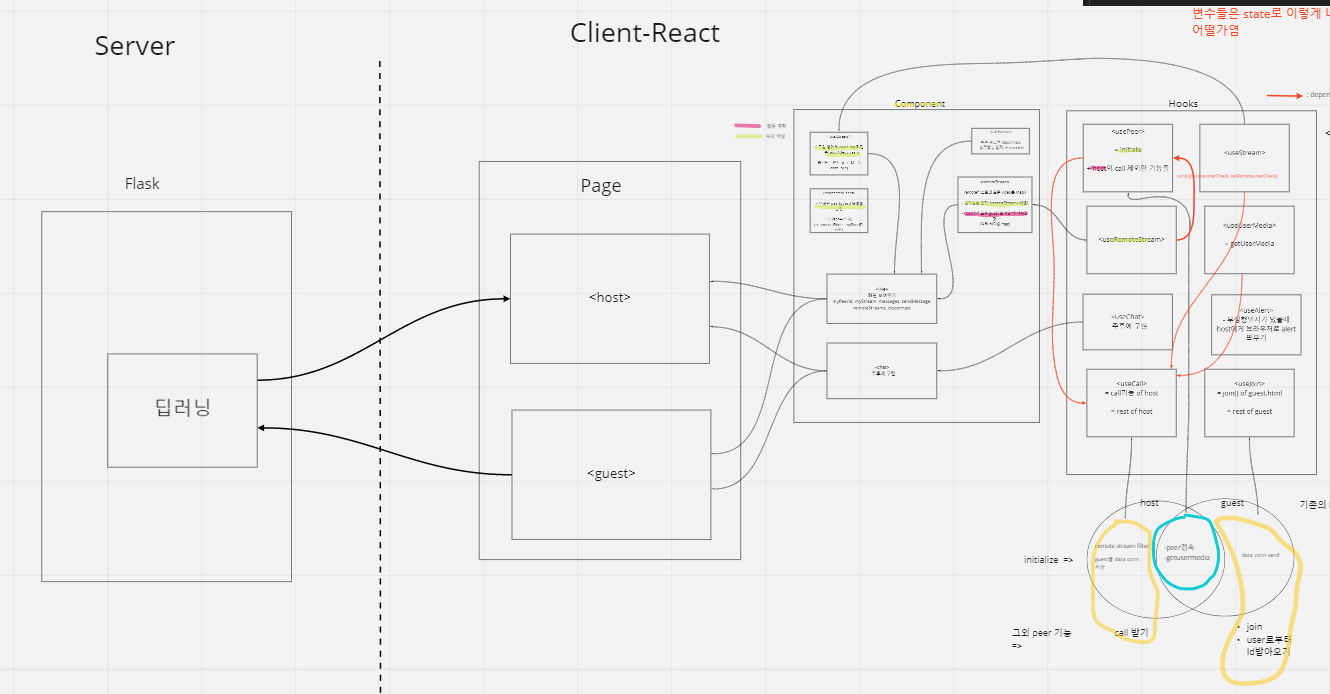
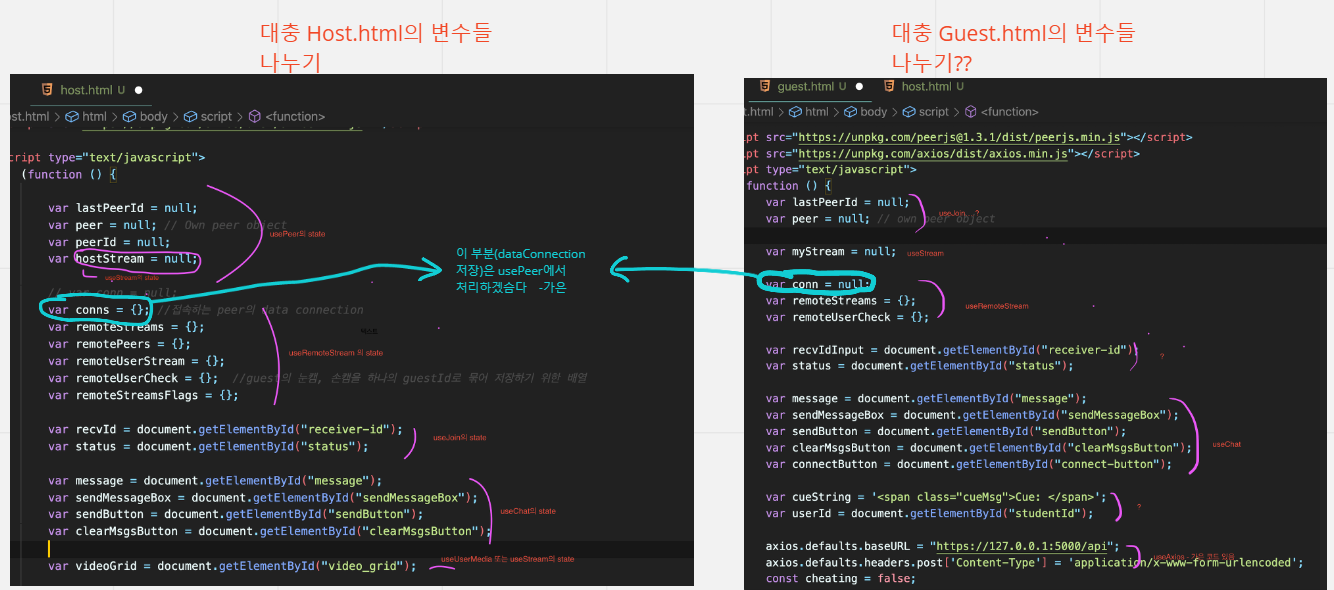
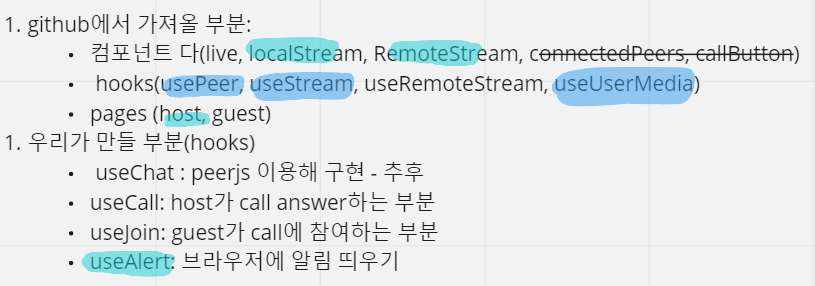
사실 flask에서 작성된 웹 페이지 코드를 react hook를 사용해서 다시 정리하려고 하였다. 그래서 코드들을 react component로 재정의하고 정리했는데 결과적으로 마음처럼 작동이 잘 되지 않아 다시 flask로 돌아가기로 했다...